ChiSquareX at TextGraphs 2020 Shared Task: Leveraging Pretrained Language Models for Explanation Regeneration
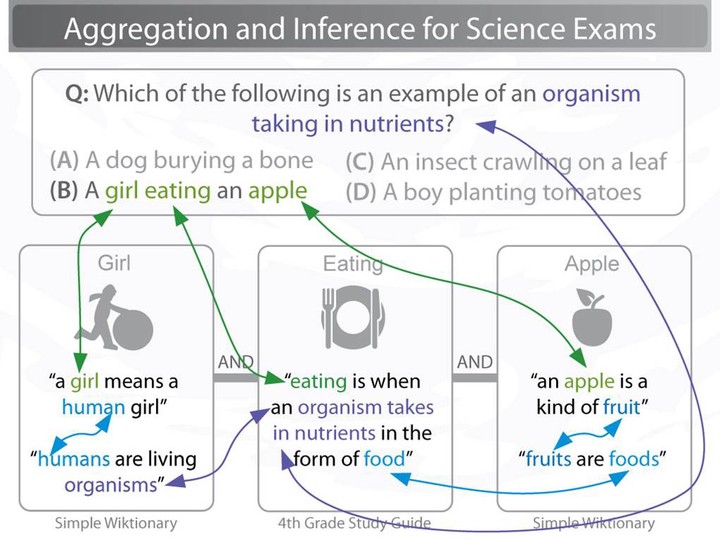 An Example Multi-hop Inference problem
An Example Multi-hop Inference problem
Abstract
In this work, we describe the system developed by a group of undergraduates from the Indian Institutes of Technology for the Shared Task at TextGraphs-14 on Multi-Hop Inference Explanation Regeneration (Jansen and Ustalov, 2020). The shared task required participants to develop methods to reconstruct gold explanations for elementary science questions from the WorldTreeCorpus (Xie et al., 2020). Although our research was not funded by any organization and all the models were trained on freely available tools like Google Colab, which restricted our computational capabilities, we have managed to achieve noteworthy results, placing ourselves in 4th place with a MAPscore of 0.49021in the evaluation leaderboard and 0.5062 MAPscore on the post-evaluation-phase leaderboard using RoBERTa. We incorporated some of the methods proposed in the previous edition of Textgraphs-13 (Chia et al., 2019), which proved to be very effective, improved upon them, and built a model on top of it using powerful state-of-the-art pre-trained language models like RoBERTa (Liu et al., 2019), BART (Lewis et al., 2020), SciB-ERT (Beltagy et al., 2019) among others. Further optimization of our work can be done with the availability of better computational resources.