Hi there!
I am Devansh Chandak, a third year undergraduate at the Department of Computer Science and Engineering at the Indian Institute of Technology, Bombay. I am fascinated by all areas of Computer Science and what it can do.
I have experience in deep learning, quantitative analytics, software development, algorithmic trading, cryptography and verification.
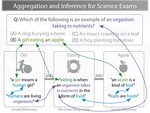
Recently, I a co-authored a publication at the COLING 2020 conference. It was on Multi-Hop Inference for Explanation Regeneration, a shared task in Textgraphs-14.
Currently, I am working as a Software Engineering Intern at Microsoft in the Azure Compute Group at IDC. I am working on OneFleet Autopilot.
Please go through the website to have a look at my internship and research experience, projects and skills. To get a better insight on my life and my achievements so far, you can have a look at my Curriculum Vitae/ Resume.
Interests
- Deep Learning & Natural Language Processing
- Software Development
- Cloud Computing
- Database and Information Systems
- Artificial Intelligence
- Quantitative Finance & Algorithmic Trading
- Cryptography & Verification
Education
-
BTech in Computer Science, 2018 - Present
Indian Institute of Technology, Bombay